GoodAir : Pipeline ETL Robustes pour la Qualité de l'Air et Météo
Apr 2026Conception, modélisation et développement d'une architecture de collecte et de traitement de données météorologiques et de qualité de l'air pour un laboratoire de recherche.
Contexte : La genèse du projet “GoodAir”
Dans le cadre de ma formation en ingénierie des données, nous travaillons sur un projet fil rouge qui s’étend tout au long de notre cursus et qui fait l’objet de nos évaluations. Ce projet est découpé en plusieurs phases fonctionnelles : audit, conception, développement, exploitation et administration/pilotage.
L’entreprise fictive TotalGreen, travaillant dans le secteur des énergies renouvelables, a décidé de développer son pôle R&D en créant GoodAir : un laboratoire de recherche pour étudier la qualité de l’air et de l’eau en France. L’objectif ? Suivre ces indicateurs pour proposer des recommandations à la population, étudier les conséquences du changement climatique et déterminer des seuils d’alerte.
L’équipe du laboratoire (climatologues, biologistes, météorologues) a besoin de se reposer sur des données fiables, disponibles et pertinentes. Dans une optique de maîtrise des coûts, le directeur souhaite se baser sur des sources existantes. Notre mission a donc été de concevoir et mettre en place une plateforme Big Data pour récupérer, stocker et préparer ces informations.
Ce projet me tient particulièrement à cœur car il m’a permis d’appliquer une multitude de concepts, de principes d’ingénierie, de méthodologies, et surtout d’acquérir une véritable vision “système”. J’y ai concrètement compris comment certains facteurs techniques et architecturaux affectent la qualité de la donnée.
Le Cahier des Charges et les Contraintes initiales
Pour répondre à ce besoin, nous avons utilisé deux sources de données principales :
Les données relatives à la qualité de l’air Les données météorologiques
Nous avons dû composer avec des contraintes strictes :
- Coûts : Utilisation formelle et exclusive de la formule gratuite (Free Tier) des APIs.
- Historisation & Fréquence : Les APIs fournissent du temps réel. Le pipeline doit tourner chaque heure pour capturer, historiser et stocker la donnée.
- Sécurité & RGPD : L’ensemble des traitements et des entrepôts doivent être localisés en France ou dans l’Union Européenne. L’accès doit être sécurisé.
- Qualité et Fiabilité : Mise en place d’une surveillance de la qualité des données, de processus de nettoyage, et de systèmes d’alerte.
- Gestion de projet : Approche itérative. Avant de nous lancer dans le développement complet, nous avons appliqué le principe de Pareto (80/20) pour livrer un MVP (Minimum Viable Product) fonctionnel.
- Licence : Utilisation des technologies open-source ou gratuites pour respecter les contraintes budgétaires du laboratoire tout en tenant compte de leurs licences respectives.
Phase 1 : Audit et Compréhension des Sources de Données
Avant d’écrire la moindre ligne de code, nous avons réalisé un audit complet de l’existant. Cette phase nous a permis de comprendre les caractéristiques de nos sources (du JSON fortement imbriqué) et de réaliser que nous n’avions aucun contrôle sur ces sources.
Voici les questions fondamentales que nous nous sommes posées, et nos réponses :
- Quelles sont les caractéristiques les plus essentielles de notre source de données ? Réponse : Du JSON issu de deux APIs distinctes.
- Comment les données sont-elles stockées dans le système source ? Réponse : Les APIs tierces fournissent du temps réel. L’historique gratuit n’est pas disponible de manière illimitée. Nous devons donc capturer la donnée sur le moment.
- C’est quoi le niveau de consistance et la fréquence des erreurs ? Réponse : Les erreurs de type “donnée corrompue” sont rares. En revanche, les erreurs de type “réseau” (Timeout HTTP 408, Service Indisponible 503, Quotas 429) peuvent survenir quotidiennement.
- Quel est le schéma des données ingérées ? Devrons-nous joindre plusieurs systèmes ?
Réponse : Le schéma source est fortement dénormalisé et imbriqué (ex:
main.temp,iaqi.pm25.v). Un gros effort de modélisation est requis. Nous devrons aplatir (Flatten) ces JSON et croiser deux systèmes distincts (Météo et Pollution) au sein d’une seule table de faits. - Si le schéma change (Schema Drift), comment allons-nous gérer cela ? Réponse : À l’ingestion (Python), nous extrayons le JSON complet sans filtrage pour garantir que tout nouveau champ soit sauvegardé dans notre Data Lake (zone Bronze). À la transformation, notre code agit comme une douane stricte (Data Contract) : il extrait uniquement ce qui est attendu par SQL Server et crashe proprement si un champ critique disparaît. Modifier la structure de la base SQL reste une décision métier, pas un automatisme risqué.
- À quelle fréquence les données seront extraites ? Réponse : Par lots (Batch) avec une fréquence d’une fois par heure.
Point fort de l’audit
Les données issues des APIs présentent une base solide. Les réponses JSON contiennent les indicateurs essentiels (AQI, PM2.5, PM10, NO₂, O₃, température, humidité, vent). Cet audit nous a aussi permis de revoir notre périmètre : nous sommes passés de 3 villes initiales à 11 villes surveillées pour garantir un volume de données suffisant pour les futurs cas d’usage analytiques.
Point de vigilance
- Données manquantes : Certaines villes ne fournissent pas tous les indicateurs (ex: Franconvile ne mesure pas l’O₃). Nous devons gérer ces absences de manière intelligente (garder les nulls légitimes, éviter les imputations hasardeuses).
- Les APIs fournissent des formats de date différents (ex:
dten timestamp Unix pour la météo,time.sen string ISO pour la pollution). - Dépendance à une source tierce : Nous n’avons aucun contrôle sur la disponibilité ou la structure des données. En cas de non disponibilité d’une API pendant une période prolongée, nous devrons envisager des sources alternatives (ex: France Météo) ou des stratégies de fallback.
- Quota des APIs Dans le cahier des charges, il est précisé que nous devons respecter les limites de la formule gratuite des APIs.
Phase 2 : Modélisation Dimensionnelle (Le Data Warehouse)
Après avoir identifié les champs communs et cruciaux, nous sommes passés à la modélisation de notre entrepôt de données (Data Warehouse).
Nous avons opté pour une modélisation en étoile (Star Schema) modèle de Kimball, avec une table de faits centrale et deux tables de dimensions :
DimTemps
│
│ FK (IDTemps)
│
FactMesures ───┤
│
│ FK (IDLieu)
│
DimLieux
Le choix d’une seule table de faits (Justification Architecturale)
Ce schéma, qui a fait l’objet de nombreux débats au sein de l’équipe, s’est imposé pour des raisons très pragmatiques :
Le même niveau de détail (Le Grain) : Le grain de notre table est strict : 1 exécution = 1 heure = 1 ville. La météo et la qualité de l’air partagent ce même grain. Les séparer obligerait les chercheurs à faire des jointures complexes pour comparer l’impact de l’humidité sur la pollution.
Time Bucketing (Heure garantie) : On ignore les timestamps fournis par les APIs (sujets aux décalages réseau et ont des formats différents) et on force l’utilisation de l’heure officielle du lancement du pipeline Airflow. On garantit ainsi qu’une ligne correspond à une heure pile (ex: 14h00).
Suivi facile des pannes : La table contient les statuts MeteoStatus et AirStatus. Si l’API météo tombe en panne, on le voit directement sur la ligne, tout en conservant les données de pollution.
Code Staging simplifié : Une seule table finale signifie un code ETL plus léger. Nous n’avons besoin que d’une seule table temporaire (Staging.FactMesures_Temp) et d’une seule requête MERGE pour enregistrer les informations.
Organisation des schémas SQL
- Schéma Gold : Le Data Warehouse analytique (FactMesures, DimLieux, DimTemps) accessible aux chercheurs.
- Schéma Ref : Le référentiel statique (Ref.Pays, Ref.SeuilsOMS, Ref.DataCatalog). Séparer ces tables, dont le cycle de vie est mis à jour manuellement, permet d’appliquer des permissions différentes et garantit une source de vérité unique.
- Schéma Staging : Zone de transit sans index ni contraintes, vidée par TRUNCATE à chaque exécution.
Phase 3 : Architecture Technique et Choix Stratégiques
Pour la première phase de ce projet, nous sommes partis sur une architecture monolithique et On-Premise (conteneurisée en local via Docker). Pourquoi ? Pour garder la maîtrise totale dans un labo de recherche naissant, simuler l’environnement de production de manière gratuite, et s’assurer de la conformité RGPD avant toute migration Cloud.
Volumétrie estimée
Pour onze villes, deux API et une collecte horaire, le système effectue:
11 villes × 24 heures = 264 appels par API et par jour ;
264 × 2 API = 528 appels API par jour ;
donc environ 192 720 appels API par an
Cette volumétrie reste relativement faible à l’échelle d’un projet. Elle ne justifie pas l’utilisation d’une architecture distribuée ou d’une technologie NoSQL orientée Big Data comme Cassandra.
Une base relationnelle analytique telle que Microsoft SQL Server est largement suffisante pour stocker, historiser et interroger les données du projet. Ce constat a directement orienté le choix d’un Data Warehouse relationnel pour la couche Gold ainsi que l’utilisation de Pandas pour les traitements ETL, sans recourir à des technologies distribuées comme Apache Spark.**
Choix technologique
| Technologie | Justification | Alternative envisagée |
|---|---|---|
| LocalExecutor (Airflow) | 10 villes, 1 DAG horaire = pas besoin de workers distribués. Économise de la RAM. | CeleryExecutor (si le volume augmente) |
| MinIO | S3-compatible, tourne en local, gratuit. Simule un vrai Data Lake. | Stockage fichier local classique |
| Star Schema | Simplifie les requêtes BI pour les utilisateurs finaux. | Tables séparées (Météo / Air) |
| Pandas | Compatibilité native avec SQLAlchemy et volume faible (< 1M lignes). | Polars (envisagé pour la V2) |
| Config JSON | Ajouter une ville se fait en ajoutant une ligne dans un fichier JSON, sans toucher au code. | Table SQL Ref.VillesCibles (en V2) |
Pour plus de détails sur notre benchmark des outils et technologies, voir : Choix technologiques du projet
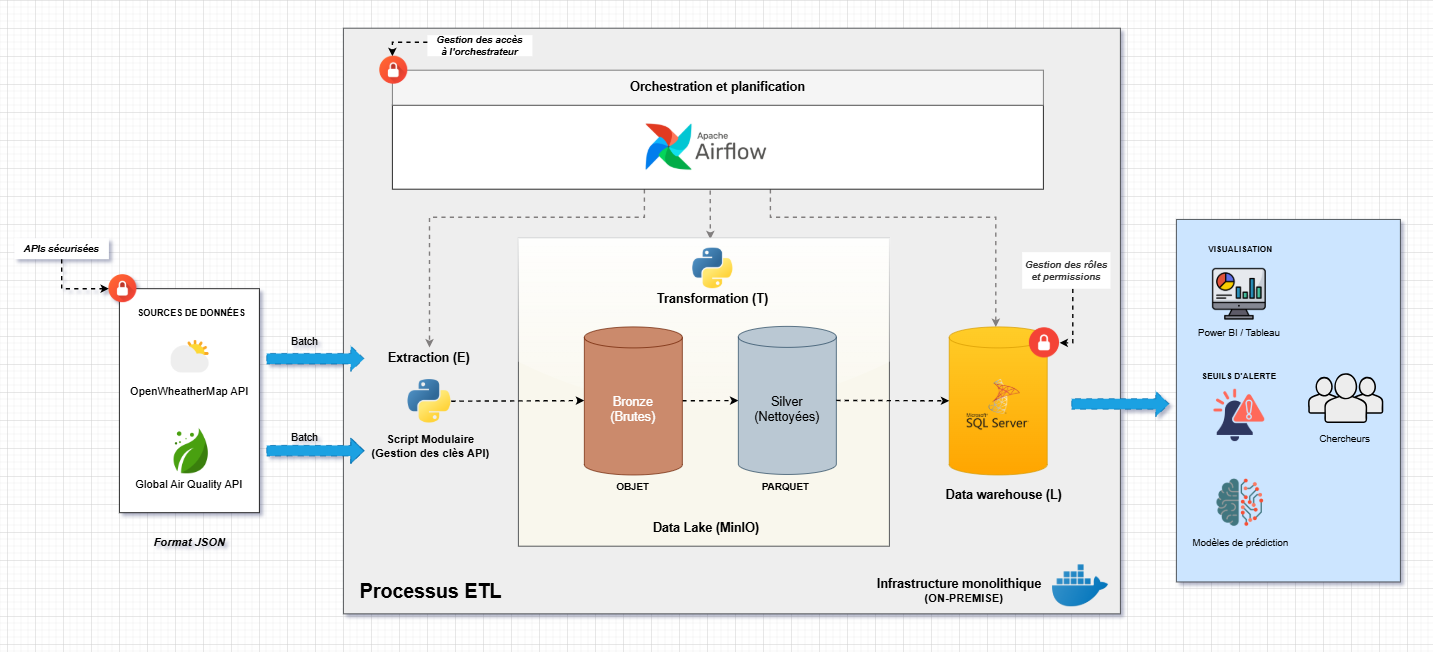
Phase 4 : Stratégie de Stockage - Le Data Lake (MinIO)
Pourquoi séparer un Data Lake d’un Data Warehouse ? Le Data Lake (MinIO) stocke les données brutes et intermédiaires pour le pipeline ETL (format JSON/Parquet), tandis que le Data Warehouse (SQL Server) sert les données structurées et croisées aux utilisateurs finaux via des requêtes SQL.
Notre Data Lake adopte une architecture par zones (similaire à l’architecture Medallion) :
Zone Bronze (JSON brut) : Son rôle est de figer l’histoire. On y sauvegarde la réponse exacte de l’API. La règle d’écriture est l’écrasement (overwrite) pour garantir l’idempotence.
Zone Silver (Parquet) : Données fusionnées, typées et nettoyées. Le format Parquet offre une compression native, la préservation des types SQL, et une lecture sélective performante. Cette zone contient un dossier mesures/ (données valides) et un dossier rejects/ (données mortes archivées pour analyse).
Le Partitionnement : La clé de l’idempotence
Chaque fichier est stocké selon une clé de partition.
year=YYYY/month=MM/day=DD/hour=HH
Pourquoi ce choix ? Il correspond exactement au grain de notre pipeline (1 exécution = 1 heure). Cela permet un accès ciblé pour une ville à une heure donnée, sans avoir à lire l’ensemble du bucket, et surtout une idempotence naturelle (le chemin généré par Python est totalement déterministe).
Pour résumé, notre architecture suit le pattern Médaillon en 3 couches. À gauche, les deux APIs sources : OpenWeatherMap pour la météo et AQICN pour la qualité de l’air. Au centre, le Data Lake MinIO avec deux zones : Bronze qui stocke les réponses JSON brutes telles quelles, et Silver qui contient les données nettoyées et fusionnées en Parquet. À droite, le Data Warehouse SQL Server avec le star schema final. Le tout est orchestré par Airflow qui déclenche le pipeline toutes les heures. Si une API tombe, le pipeline continue avec l’autre, on ne perd jamais tout. Les données traversent toujours le même chemin : Extract vers Bronze, Transform vers Silver, Load vers Gold. Jamais de retour en arrière.
Phase 5 : Principes de Développement du Pipeline ETL
On pense souvent qu’un bon pipeline est un pipeline qui “tourne” toujours. C’est faux. Le travail le plus important d’un ingénieur de données est d’assurer la véracité des données. Si l’ingénieur ne garantit pas cette véracité, il ne fait pas du Data Engineering, il fait du Data Moving. Un pipeline qui tourne mais qui génère de la mauvaise donnée est un pipeline toxique.Un pipeline de traitement doit etre conçus pour l’échec, autrement dit, il doit être conçu pour échouer de manière contrôlée et informative afin de resourdre les problèmes rapidement et efficacement et garantir la qualité des données
Voici les principes cardinaux que nous avons appliqués :
Fail Fast (Crash tôt, crash fort) : Ne pas cacher les erreurs avec des try/except abusifs. Si une API renvoie une erreur 500, le code doit crasher pour que Airflow le détecte et gère le retry.
Design for Failure : Le réseau va faillir, les limites d’API seront atteintes. Nous gérons cela via la résilience automatique d’Airflow (retries après 5 minutes).
Idempotence : Exécuter le pipeline 10 fois pour la même heure doit donner exactement le même résultat en base. Nous l’assurons via le partitionnement S3 (Overwrite), le TRUNCATE du staging, et le MERGE (Upsert) dans SQL Server.
Séparation des responsabilités : Airflow ne fait que de l’orchestration. Python gère la logique métier. SQL Server gère le stockage et l’intégrité.
Pilotage par configuration : Le code ne contient pas de données “en dur”. Les villes, les URLs et les paramètres sont dans des fichiers .yaml, .json ou .env. Par exemple pour ajouter une ville, il suffit d’ajouter une ligne dans
cities_config.json:
[
{"city": "Paris", "country": "FR"},
{"city": "Lyon", "country": "FR"},
{"city": "Lille", "country": "FR"},
{"city": "Bordeaux", "country": "FR"},
{"city": "Marseille", "country": "FR"},
{"city": "Toulouse", "country": "FR"},
{"city": "Nantes", "country": "FR"},
{"city": "Strasbourg", "country": "FR"},
{"city": "Nice", "country": "FR"},
{"city": "Rennes", "country": "FR"},
{"city": "Franconville", "country": "FR"}
]
Phase 6 : Gestion de la Qualité des Données (Data Quality)
Puisque nous ne contrôlons pas les sources, le pipeline est fondamentalement défensif. Mais attention à l’Alert Fatigue : il ne faut pas tout vérifier, il faut vérifier ce qui compte.
Voici nos règles de gestion appliquées dans la zone Silver (via Pandas) :
Cohérence de la source de vérité : Le “Nom de la ville” ne vient jamais de l’API (qui est parfois formatée différemment selon le fournisseur), mais toujours de notre fichier de configuration.
Typage strict : Utilisation de pd.to_numeric(…, errors=“coerce”) pour transformer silencieusement les chaînes aberrantes en NULL.
numeric_cols = ["Temperature", "Humidite", "Pression", "VitesseVent",
"AqiGlobal", "PM25", "PM10", "NO2", "O3"]
for col in numeric_cols:
df[col] = pd.to_numeric(df[col], errors="coerce") # "abc" → NULL
Règles sur les valeurs manquantes :
- Température NULL : On la maintient telle quelle. Mettre 0°C fausserait les moyennes.
- PM2.5 ou O3 NULL : On maintient. Toutes les stations IoT ne mesurent pas tout.
- Statuts de source (MeteoStatus, AirStatus) : On marque la source comme FAILED uniquement si toutes les métriques de la source sont vides.
Détection des Lignes Mortes : Une ligne avec toutes les métriques vides n’a aucune valeur analytique. Elle est rejetée et archivée.
DQ Flags : Au lieu de supprimer une ligne avec une température extrême (ex: -45°C), on la marque avec un flag booléen (is_temp_valid). Le chercheur décidera de l’inclure ou non.
Data Contracts : Juste avant l’insertion en base, un assert valide strictement que toutes les colonnes attendues par SQL Server sont présentes.
expected_cols = [
"NomVille", "IDTemps", "Temperature", "Humidite", "Pression",
"VitesseVent", "AqiGlobal", "PM25", "PM10", "NO2", "O3",
"MeteoStatus", "AirStatus"
]
assert all(col in df.columns for col in expected_cols), \
f"Colonnes manquantes. Attendu: {expected_cols}, Reçu: {list(df.columns)}"
- Dernière ligne de défense : Le moteur SQL lui-même impose ses contraintes (Clés primaires composites, Clés étrangères, CHECK (Humidite BETWEEN 0 AND 100)).
Phase 6.5 : Les “Plus” de notre Architecture (Gouvernance, Sécurité et Métier)
Un pipeline ETL ne se limite pas à déplacer de la donnée. Ce qui différencie un simple script d’une plateforme Enterprise-Ready, c’est la gouvernance, la sécurité et la compréhension du métier. Voici les aspects avancés que nous avons intégrés à GoodAir :
1. Le Nettoyage Analytique (Métier vs Technique)
Avant même d’appliquer nos règles métier, notre code Python effectue un filtrage technique strict (cast strict des types, dédoublonnage sur la clé logique (NomVille, DateHeure) en gardant l’enregistrement le plus récent).
Ensuite, nous appliquons un Nettoyage Métier basé sur un principe de résilience : on ne rejette une ligne complète que si elle est totalement inexploitable.
| Scénario (Donnée Manquante) | Action Appliquée | Justification Analytique / “Expert” |
|---|---|---|
| Ville ou Heure manquante | REJET (Drop Row) | Une mesure sans lieu ou sans repère temporel (Clés logiques) n’a aucune valeur dans un Data Warehouse. |
| Code Pays manquant | Remplacé par ‘ND’ | La ville suffit pour l’identifier analytiquement. On ne rejette pas la ligne pour ne pas casser les filtres BI sur le pays. |
| Coordonnées GPS manquantes | Garder NULL | Empêche l’affichage sur une carte, mais les mesures (ex: PM2.5) restent parfaitement valides pour les graphiques temporels. |
| Métrique Météo manquante | Garder NULL | Remplacer une température vide par 0 fausserait les moyennes (car 0°C est une vraie température). Les fonctions SQL d’agrégation (AVG) ignoreront naturellement le NULL. |
| Polluant manquant (ex: O3) | Garder NULL | Toutes les stations IoT ne mesurent pas tous les polluants l’hiver. Rejeter la ligne ferait perdre d’autres données valides (PM2.5). |
| Pluie ou Neige manquante | Remplacer par 0 | Dans les APIs Météo, l’absence de la clé “Rain” signifie “il ne pleut pas”. L’imputation par 0 est la seule méthode correcte ici. |
2. Le Data Catalog et les Requêtes Métier prêtes à l’emploi
Pour que la donnée soit réellement utile, elle doit être documentée. Nous avons mis en place un Data Catalog rigoureux. Au sein de notre schéma de référence (Ref), nous documentons les définitions exactes des colonnes, l’origine de la donnée, et les unités de mesure.
En plus de ce catalogue, nous avons regroupé des requêtes métier SQL (ex: Température moyenne par ville). Les chercheurs n’ont pas à chercher comment faire des jointures complexes : l’accès à l’information est immédiat.Pour plus sur les requêtes métier prêtes à l’emploi : Requêtes SQL prêtes à l’emploi
3. Le Lignage de Données (Data Lineage)
Comment savoir si une donnée présente dans un tableau de bord est fiable ? Nous avons intégré un système de traçabilité et d’audit directement dans notre table de faits (Gold.FactMesures). Chaque ligne insérée porte les métadonnées suivantes :
MeteoStatusetAirStatus(OKouFAILEDselon la disponibilité des données sources).DateInsertionetDateModification(gérées automatiquement viaGETDATE()par SQL Server).IDBatch: Correspond aurun_idd’Airflow. C’est crucial : si un run d’Airflow a corrompu la base avec des données fausses, nous pouvons faire un rollback ciblé et supprimer uniquement les données associées à cetIDBatchprécis.
4. Sécurité et Matrice des Accès (RBAC)
Puisque nous hébergeons des données sensibles, la sécurité est primordiale. L’accès au Data Warehouse est régi par un contrôle d’accès basé sur les rôles (RBAC - Role-Based Access Control) implémenté directement via les comptes de connexion SQL Server Authentication :
| Rôle SQL | Parties Prenantes | Droits sur le Schéma Gold | Droits sur le Schéma Ref | Droits Système |
|---|---|---|---|---|
sa (Admin) | Data Engineers | FULL | FULL | Contrôle total (Création, Drop, Gestion utilisateurs) |
Role_Chercheur | Chercheurs (Climat, Bio) | SELECT | SELECT | Accès en lecture seule aux données analytiques. |
Role_Directeur | Directeur du Labo | SELECT | SELECT | Accès aux vues consolidées. |
Role_RSSI | Responsable Sécurité | DENY | DENY | Gestion stricte des accès et des politiques de mots de passe, sans accès à la donnée brute. |
Phase 7 : Les problèmes majeurs rencontrés : La gestion temporelle et le changement d’heure (DST)
Un des plus gros défis du projet a été la gestion temporelle. Le pipeline devait enregistrer l’IDTemps sur l’heure locale française (Europe/Paris), car le métier est en France.
La solution à deux niveaux :
- Docker-compose : Interface d’Airflow configurée sur Europe/Paris.
- Python : Le logical_date interne d’Airflow reste en UTC. Nous avons dû créer une fonction to_paris_time() utilisant la librairie zoneinfo pour convertir ce datetime au tout début de la tâche. -> Pour savoir Comment le changement du fuseau horaire à été géré
Le problème du changement d’heure (DST)
- Passage à l’heure d’été : L’intervalle 2h-3h disparaît. Le pipeline saute un créneau (trou normal).
- Passage à l’heure d’hiver : L’intervalle 2h-3h se répète. Le pipeline tente d’insérer un doublon. Ce conflit de clé primaire est géré naturellement par notre logique de MERGE (Upsert). Nous réfléchissons à une solution plus élégante pour gérer ces cas extrêmes de façon automatique
Structure du Répertoire du Projet
Afin d’assurer la clarté et la maintenabilité du code, nous avons adopté la structure suivante :
GoodAirPipeline/
├── dags/ # DAGs Airflow
├── docs/ # Documentation (Data Catalog, principes de dev, etc.)
├── src/
│ ├── extract/ # Appels API → Bronze (JSON brut dans MinIO)
│ ├── transform/ # Nettoyage & DQ → Silver (Parquet dans MinIO)
│ ├── load/ # Staging → MERGE → Gold (SQL Server)
│ ├── utils/ # Connexions DB, MinIO, config, logging
│ └── sql/ # Scripts DDL, MERGE, Data Catalog
├── tests/ # Tests unitaires (Pytest)
├── config/
│ ├── cities_config.json # Villes à surveiller (pilotage par config)
│ └── pipeline_config.yaml
├── .env.example # Template des variables d'environnement
├── docker-compose.yml # Infra complète (Airflow + SQL Server + MinIO)
├── Dockerfile # Image Airflow custom (ODBC + dépendances)
├── DATA_CATALOG.md # Documentation des tables et colonnes
├── pyproject.toml # Dépendances Python (uv)
└── README.md
Prochaine Étape : L’Exploitation (Phase 2)
Maintenant que la collecte et le nettoyage sont automatisés de façon robuste, le projet évolue vers sa phase d’exploitation pour répondre concrètement aux besoins des chercheurs.
Le laboratoire a demandé des livrables spécifiques :
- Data Visualisation et BI : Préparation des requêtes pour extraire les KPIs et créer des rapports croisant météo et qualité de l’air (les options possibles sont Metabase, PowerBI ou Tableau, à définir avec mes collègues).
- Alerting : Mettre en lumière les variations extrêmes et alerter les équipes lors de dépassements de seuils (basés sur notre table Ref.SeuilsOMS).
- Data Science (Machine Learning) : Anticiper de futures analyses complexes comme la prédiction des prochaines canicules, la modélisation de la saisonnalité, et trouver les variables fortement corrélées.
Nous prévoyons également d’intégrer des tests automatisés robustes (CI/CD) sur notre code Python.
Récapitulatif des Apprentissages
Vision Architecturale Globale : Comprendre pourquoi et comment combiner un Data Lake (stockage agnostique) et un Data Warehouse (requêtage analytique).
Ingénierie de la Fiabilité : Implémenter concrètement l’idempotence, le Fail Fast, et gérer la complexité des fuseaux horaires (DST) en production.
Data Quality Stratégique : Apprendre à ne pas sur-nettoyer la donnée (Alert fatigue, préservation des nulls légitimes) tout en blindant le pipeline via des Data Contracts et des contraintes SQL.
Modélisation Multidimensionnelle : Maîtriser le schéma en étoile, l’importance du “Grain” de la table de faits, et la gestion d’un schéma de référence et de staging.
Liens Pertinents et Ressources
- Dépot GitHub du projet — code source complet, Docker-compose, scripts SQL, et documentation.
- Les images des résultats du projet — captures d’écran des tables SQL, des fichiers Parquet, et des logs Airflow.
- Stratégie de stockage dans le data lake MinIO — organisation, partitionnement, et sécurité des données dans MinIO.
- Stratégie Data Warehouse — modélisation, schémas, MERGE et sécurité SQL Server
- Data Catalog — documentation des tables et colonnes.
- Principes de développement — principes d’ingénierie appliqués au pipeline.
- Qualité des données — vérifications DQ appliquées à chaque étape du pipeline
Concepts Fondamentaux (Lectures)
Data Normalization Explained: The Complete Guide | Splunk
Data Normalization Explained: The Complete Guide | Splunk
The End of the Bronze Age: Rethinking the Medallion Architecture
How Modern Data Teams Work (Engineer, Analyst, Scientist, Architect, ML)