Intégration de Données avec Pentaho
Nov 2025Création d'un pipeline ETL avec Pentaho Data Integration pour consolider et nettoyer des données environnementales, en appliquant une logique métier stricte.
Contexte et Enjeux : Découverte de Pentaho
Aujourd’hui, dans le vaste monde de l’ingénierie des données, on parle beaucoup de technologies comme SQL et des stacks modernes. Cependant, on oublie qu’une majorité de structures utilisent encore des outils d’intégration de données classiques. Selon moi, il est essentiel d’avoir une bonne compréhension de ces outils pour faciliter la migration progressive des entreprises vers le Cloud, une transition qui se fait de plus en plus aujourd’hui. En tant qu’étudiant en ingénierie des données, je pense que maîtriser ces outils d’intégration est à la fois un vrai plus et un choix décisif pour pouvoir travailler facilement dans une entreprise en pleine migration, car comprendre l’existant facilite grandement la tâche.
Dans ce vaste domaine de la data, on distingue généralement plusieurs types d’outils d’intégration. Si le marché est aujourd’hui dominé par des solutions comme Talend ou Dataiku, il existe des outils plus anciens mais extrêmement robustes comme Pentaho Data Integration (PDI). Après avoir suivi un atelier sur l’intégration de données, j’ai voulu tester Pentaho comme alternative à Talend Open Studio. Bien que l’outil puisse paraître austère au premier abord, je l’ai trouvé redoutablement efficace et pertinent pour les phases de pré-nettoyage et d’intégration.
Comme à mon habitude, j’ai accompagné mon apprentissage technique d’une problématique métier concrète. J’ai simulé le cas d’une entreprise internationale spécialisée dans le développement durable. Avant d’ouvrir de nouvelles agences stratégiques en Europe, cette entreprise souhaite analyser l’état de la pollution de l’air dans quatre pays cibles : la France, l’Espagne, l’Italie et l’Allemagne.
Ma mission était claire : collecter, traiter et consolider les données de pollution et socio-économiques pour produire un tableau de bord décisionnel (via Tableau) permettant d’identifier les zones les plus polluées et leur évolution dans le temps.
Recherche et Collecte des Données
La première étape de ce projet a consisté à sourcer la donnée. Pour que l’analyse soit complète, il me fallait des indicateurs variés, tous extraits au format CSV :
- Indicateurs de pollution : PM2.5, NO2, O3.
- Indicateurs climatiques : Émissions de CO2 par habitant.
- Indicateurs socio-économiques : Part de la population urbaine, PIB par habitant.
- Données géographiques : Villes, latitudes et longitudes pour la cartographie.
- Données temporelles : Années de 2010 à 2023 pour observer les tendances.
J’ai dû consolider ces informations à partir de multiples sources fiables (Our World in Data, World Bank, Kaggle, etc.). Cependant, c’est lors de la phase de préparation de ces fichiers que j’ai été confronté à un véritable enjeu de conception.
Le Cœur du Projet : L’Art de distinguer Besoin, Spécification et Logique
Lors de la définition de mon processus de nettoyage, j’ai eu un moment de réflexion (un véritable “stop”). Au-delà du nettoyage technique classique (suppression des doublons, gestion des valeurs nulles, formatage des chaînes de caractères), je devais nettoyer mes données en respectant la réalité du terrain et les exigences de l’entreprise.
C’est ici que j’ai réalisé une nuance cruciale que l’on a souvent tendance à confondre dans notre domaine. Il fallait faire la distinction entre trois strates :
- Le besoin métier (Les décisions stratégiques) : C’est l’objectif final de l’entreprise. Dans mon cas, la stratégie dictait que l’analyse ne devait porter que sur 4 pays précis (France, Espagne, Italie, Allemagne) et sur une période temporelle stricte (2010-2023) pour définir l’emplacement des futures agences.
- Les spécifications fonctionnelles (La connaissance du domaine) : Ce sont les contraintes réelles et inaltérables de la donnée elle-même. Par exemple, sur le plan environnemental, une concentration de particules PM2.5 ne peut physiquement pas être négative ! C’est une valeur aberrante qu’il faut traiter. Conserver ici une ligne de pollution sans coordonnées géographiques (latitude/longitude) est totalement inutile pour un projet d’implantation spatiale.
- Les contraintes de qualité (Data Quality Constraints) : Ce sont les règles qui garantissent l’intégrité et la cohérence des données. Par exemple, un code pays doit être valide et correspondre à un pays existant.
- Les contraintes techniques (Technical Constraints) : Ce sont les limitations liées à l’outil ou à la plateforme utilisée. Par exemple, Pentaho peut nécessiter un tri préalable avant de faire des jointures, ou imposer des formats spécifiques pour les dates.
- La logique métier (ou Business Logic) : C’est l’application technique et informatique de tout ce qui précède. C’est le fait de traduire ces contraintes stratégiques et physiques en règles de nettoyage dans le pipeline.
Il ne servait à rien d’intégrer des données mondiales, des valeurs négatives impossibles, ou des lignes datant de 1990. J’ai donc appris à implémenter cette logique métier directement dans Pentaho pour filtrer drastiquement mon jeu de données en amont, garantissant ainsi un Dataset final parfaitement cohérent avec la réalité physique et l’objectif de l’entreprise.
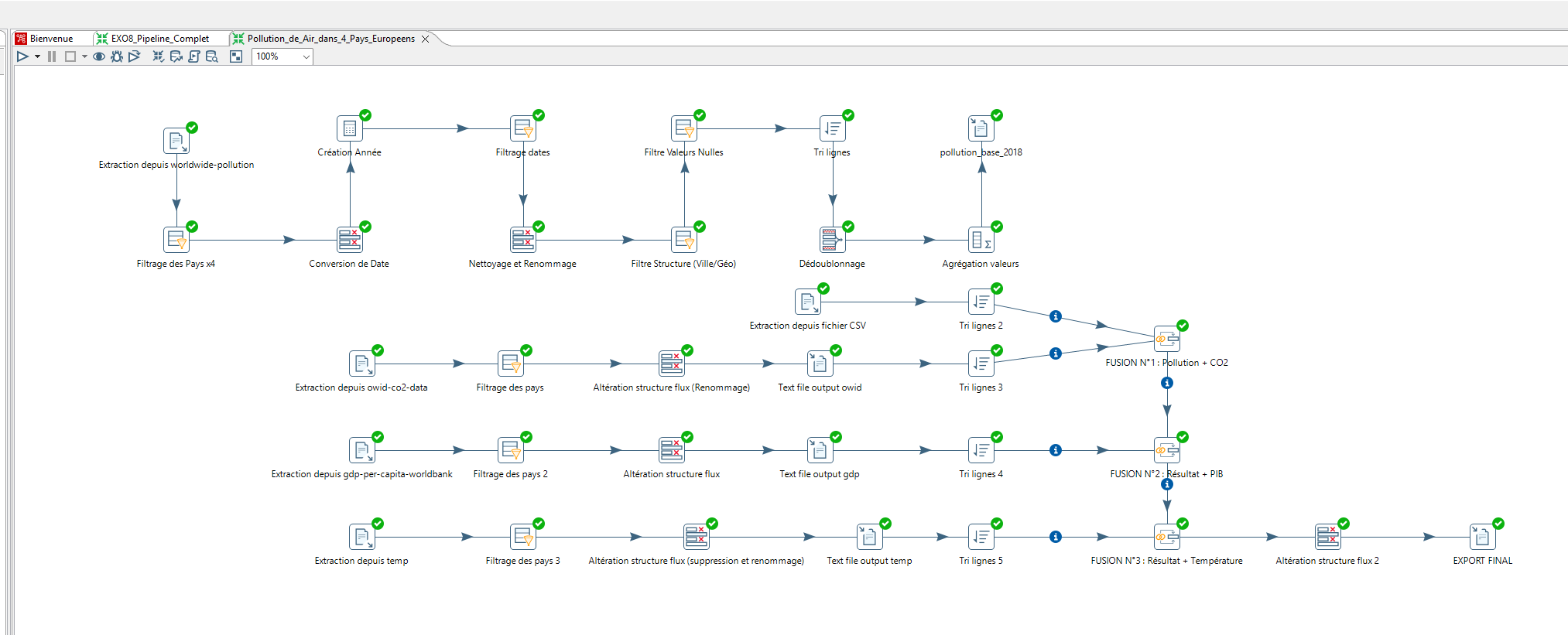
Le Pipeline de Traitement sous Pentaho
Le traitement a été réalisé en flux continu dans Pentaho, de l’extraction jusqu’à l’export, en gérant de multiples jointures.
Étape 1 : Importation des Données
J’ai chargé les différents fichiers via le step CSV File Input. Il a fallu configurer rigoureusement les délimiteurs (virgules ou points-virgules selon les sources) et typer les données (String pour les pays, Integer pour les années, Number pour les métriques de pollution).
Étape 2 : Nettoyage et Normalisation
Cette étape a été appliquée individuellement à chaque flux avant toute tentative de fusion :
- Renommage (
Select Values) : Harmonisation des clés de jointure (transformer “Entity” en “Country”, “Year” en “Annee”). - Nettoyage de texte (
String Operations) : Application de la fonction Trim sur les noms de pays et les codes pour éviter que des espaces parasites ne fassent échouer les jointures. - Filtrage métier (
Filter Rows) : C’est ici que ma logique métier est intervenue. J’ai supprimé les lignes sans Code Pays, exclu les années hors du scope 2010-2023, rejeté les valeurs environnementales aberrantes (comme des taux négatifs), et filtré les lignes avec des coordonnées géographiques nulles. - Dédoublonnage (
Unique Rows) : Suppression des doublons stricts basés sur la clé composite {Pays + Annee}.
Étape 3 : Fusion des Données (Merging)
Pour consolider tous ces indicateurs épars dans une seule table unifiée, j’ai utilisé l’année et le code pays comme facteurs de jointure.
- Tri (
Sort Rows) : Dans Pentaho, un tri ascendant sur les clés de jointure est techniquement obligatoire avant de fusionner. - Jointures en cascade (
Merge Join) : J’ai effectué des Inner Joins progressifs (Flux CO2 + Flux PIB -> Temp1 ; Temp1 + Flux Urbanisation -> Temp2 ; etc.) jusqu’à obtenir mon Dataset final complet.
Étape 4 : Export et Visualisation
Le résultat a été généré via un Text File Output (au format CSV, encodage UTF-8). Ce fichier propre et unifié a ensuite été importé dans Tableau Desktop pour créer les visualisations et le classement final des pays les plus pollués, répondant ainsi parfaitement à la commande de l’entreprise.
Récapitulatif des apprentissages
- Maturité Analytique : Compréhension et application concrète de la différence entre le besoin stratégique, la spécification fonctionnelle (la réalité du terrain) et la logique métier (l’implémentation technique).
- Maîtrise d’un outil ETL historique : Prise en main de Pentaho Data Integration, gestion des flux parallèles, des étapes de transformation (
String Operations,Select Values) et des contraintes de tri avant jointure. - Consolidation de données hétérogènes : Capacité à unifier des sources disparates (fichiers aux délimiteurs et formats différents) via des clés de jointure composites (Pays + Année).
- Vision bout-en-bout : Pilotage du cycle complet de la donnée, du sourcing brut sur Internet jusqu’à l’alimentation d’un outil de Business Intelligence (Tableau).
Annexe : Sources de Données
Indicateurs de pollution (PM2.5, PM10, NO₂, O₃) :
Indicateurs climatiques et environnementaux :
Indicateurs socio-économiques & Géographiques :